Ensaio acerca de bibliotecas de código aberto para abstração de acesso a banco de dados em linguagem C++
Este estudo é um ensaio acerca das ferramentas de programação em linguagem C++ destinadas a fornecer uma camada de abstração para operar indistintamente bibliotecas clientes nativas de servidores de banco de dados.
[ Hits: 24.365 ]
Por: Renato Merli em 20/10/2011

Introdução
Camadas de abstração de acesso a banco de dados são comuns em plataformas de desenvolvimento e disponíveis em diversas linguagens de programação. Para a linguagem C++ temos algumas opções disponíveis. Esse ensaio introduz o conceito de camadas de abstração e fornece uma analise introdutória de algumas ferramentas consideradas relevantes.
Lembre-se de que esse documento é um ensaio e, logo, pretende-se incompleto. Você pode submeter adendos e alterações através do mecanismo wiki em:
Introdução
A metodologia mais utilizada em projetos de aplicativos de acesso a banco de dados é a que faz uso da arquitetura cliente-servidor, onde o aplicativo do usuário acessa um Sistema Gerenciador de Banco de Dados (SGBD), ou servidor de banco de dados, através de uma rede de computadores.Nessa arquitetura o aplicativo do cliente é responsável por interagir com o usuário através de uma interface gráfica, enviando comandos ao SGBD, que por sua vez é responsável por armazenar e recuperar dados.
Existem diversos SGBDs disponíveis, como Oracle, MySQL, Firebird etc. Cada um deles utiliza mecanismos próprios de comunicação, autenticação e representação dos dados resultantes das consultas. Ou seja, cada um deles opera segundo protocolos próprios de comunicação e aquisição de dados.
Dessa forma, um aplicativo cliente, aquele que interage com o usuário e opera os dados através do SGBD, deve ser capaz de comunicar-se com o servidor segundo o protocolo de comunicação próprio do SGBD em questão.
Os servidores SGBD normalmente vem acompanhados de softwares (mais especificamente, bibliotecas de programação conhecidas como "bibliotecas cliente") que fornecem funcionalidades para conectar-se ao servidor e realizar operações.
As bibliotecas cliente fornecidas juntamente com um SGBD são compatíveis apenas com o SGBD ao qual estão associadas, sendo incapazes de operar com outros servidores. por isso são também são chamadas de bibliotecas cliente nativas.
O diagrama abaixo representa a arquitetura de um aplicativo que acessa SGBD's através de bibliotecas nativas.
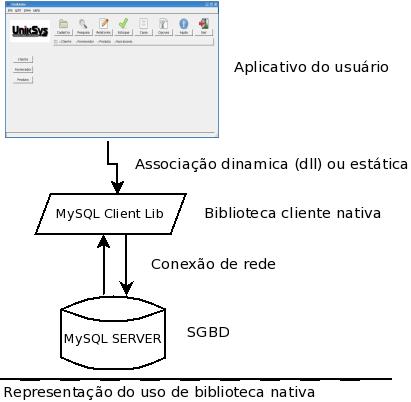
- Dependência do SGBD em questão, já que a biblioteca nativa acessa apenas o SGBD para o qual foi criada;
- Dependência de plataforma de software e hardware, já que o aplicativo que faz uso da biblioteca nativa poderá operar apenas nas plataformas em que a biblioteca nativa também opera.
Além disso, o uso de bibliotecas nativas torna-se questionável se analisarmos as várias bibliotecas de abstração de acesso a SGBDs existentes para linguagem C++.
Bibliotecas de abstração fornecem uma API genérica para acesso aos recursos de diferentes servidores, permitindo independência de SGBD, além de oferecer diversos recursos extras, métodos próprios para manipulação dos diferentes tipos de dados e, em alguns casos, componentes gráficos para correta apresentação desses dados em interfaces gráficas (GUIs).
Essas ferramentas são consideradas camadas de abstração, pois fazem uso das bibliotecas nativas de acesso as diferentes fontes de dados, ao mesmo tempo que fornecem ao programador uma única interface de programação, permitindo que diferentes SGBDs sejam acessados e operados de forma indistinta.
O diagrama abaixo representa a arquitetura de um aplicativo que acessa SGBDs através de camada de abstração.
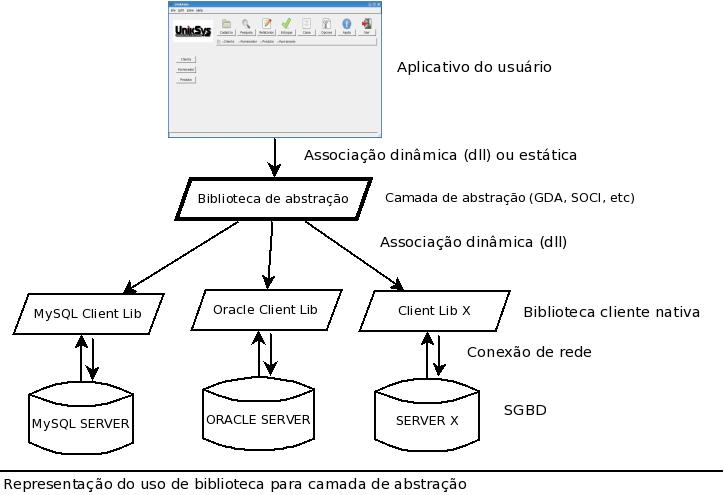
- Independência de SGBD: Uma mesma biblioteca de abstração normalmente opera sobre bibliotecas nativas de vários servidores de banco de dados diferentes. Isso propicia independência de servidor de banco de dados, tornando possível migrar entre diferentes SGBDs sem alterar o código. Essa funcionalidade, mesmo considerada isoladamente, seria suficiente para justificar o uso de camadas de abstração para a grande número das aplicações;
- Representação facilitada para tipos de dados: Bibliotecas de abstração de SGBDs normalmente utilizam uma representação genérica para tipos de dados próprios de cada SGBD, fazendo as conversões necessárias e, desse modo, facilitando a portabilidade entre SGBDs diferentes;
- Uso de recursos modernos da linguagem C++: algumas bibliotecas de abstração fazem uso de modernos recursos de STL e Boost, como contêineres e tipos de dados como o 'tuple' [11]', além de sintaxe inspirada em streams;
- Sintaxe facilitada: Algumas bibliotecas fazem uso criativo de polimorfismo e sobrecarga de operadores para permitir operações utilizando sentenças curtas e legíveis, facilitando a criação de instruções SQL e subsequente tratamento dos dados resultantes;
- Operação em ambiente multi-thread: mesmo que a biblioteca nativa do SGBD não seja thread-safe, a biblioteca de abstração pode cuidar do acesso concorrente permitindo a operação segura em ambientes multi-thread;
- Conformidade com padrões e independência de plataforma: As bibliotecas apresentadas aqui são concordantes com padrões e, em principio, portáveis entre várias plataformas e compiladores;
- Manutenibilidade: as bibliotecas estudadas aqui são softwares de código aberto, permitindo manutenção, depuração, extensão e alterações de forma facilitada, caso contrario ao da maioria das bibliotecas nativas de acesso a SGBDs;
- Funcionalidades inéditas: algumas bibliotecas implementam facilidades que não estão presentes de forma facilitada na biblioteca nativa de acesso ao SGBD;
- Acesso a fontes de dados alternativas: algumas bibliotecas foram projetadas para acessar fontes de dados pouco populares ou não concordantes com a linguagem de consulta SQL, como servidores LDAP, arquivos CSV, MySQL, arquivos Microsoft Access ou bancos de dados Berkeley DB;
- Criação de sentenças SQL: algumas bibliotecas fornecem ferramentas para facilitar a criação de querys no padrão SQL através de uma metodologia simplificada. Esse método pode gerar consultas otimizadas e adaptadas a cada tipo de servidor de banco de dados em particular a partir de uma construção padrão única;
- Arquitetura modular: a maioria das bibliotecas de abstração são projetadas segundo uma arquitetura modular, permitindo a criação de extensões para acesso a novas fontes de dados de forma facilitada.
O uso de uma arquitetura de camada de acesso intermediária aos recursos das bibliotecas nativas (camada de abstração) também oferece algumas desvantagens, sendo as principais:
- Isolamento dos recursos da biblioteca de acesso nativa: nem todos os recursos da biblioteca nativa podem estar disponíveis através da camada de abstração, que busca reunir o conjunto de funcionalidades presentes na maioria das bibliotecas nativas. Embora normalmente bibliotecas de abstração forneçam acesso direto à biblioteca nativa, essa pratica deve ser evitada, pois vai contra os princípios da utilização de uma camada de abstração, tornando o aplicativo dependente de um SGBD em particular;
- Overload: as bibliotecas de abstração são uma camada de acesso as bibliotecas nativas e, desse modo, é de se esperar que apresentem alguma perda de desempenho. Entretanto, testes de desempenho realizados pelos criadores de algumas bibliotecas de abstração mostram que essa perda é pouco significativa e não justifica desconsiderarmos o uso dessas ferramentas na grande maioria dos casos. Você deve consultar o site oficial de cada biblioteca para maiores informações sobre desempenho.
Existem diversas bibliotecas multiplataforma para abstração de acesso a SGBD's disponíveis para linguagem C++. Para esta versão deste documento, estudaremos três das ferramentas que consideramos relevantes: GDAmm [1] , SOCI [2] e DBIxx [3].
Outras bibliotecas viáveis são citadas brevemente na conclusão deste ensaio.
2. GDAmm
3. SOCI
4. DBIxx
5. Outras ferramentas e referências
Introdução à plataforma GNU de desenvolvimento
PostgreSQL - Embutindo comandos SQL no seu código C
Embutindo um banco de dados SQLite em sua aplicação C++
Acessando PostgreSQL com C - Cursores
Oi Renato,
Ótima coletânea!
Abraço!
Este é um ensaio interessante e informativo. Acho que você tem a oportunidade de participar de competições e outros sistemas de avaliação. Agora também estou interessado na minha pesquisa e quero escrever um ensaio, desde que eu leia bons e instrutivos exemplos em https://carnavalderedacao.com.br/ você também pode aprender algo lá. Eu me pergunto o que você tem um ensaio muito científico e educacional, você mesmo o escreveu? Afinal, se sim, talvez você seja um professor? Se você não se importar, levarei seu projeto para o trabalho.
Patrocínio

Destaques
Artigos
Maquina modesta - a vez dos navegadores ferrarem o usuario
Fscrypt: protegendo arquivos do seu usuário sem a lentidão padrão de criptograr o disco
Faça suas próprias atualizações de pacotes/programas no Void Linux e torne-se um Contribuidor
Como rodar o Folding@home no Linux
Criando um painel de controle (Dashboard) para seu servidor com o Homepage
Dicas
Utilizando a Ferramenta xcheckrestart no Void Linux
Pisando no acelerador do Linux Mint: Kernel XanMod, zRAM e Ajustes de Swap
Como compilar kernel no Linux Mint
Tópicos
como usar o caja como cliente FTP no linux mint? (6)
(CLIPPER) Rodando o mesmo código tanto no Windows quanto no Linux (1)
O que você está ouvindo agora? [2] (247)
Top 10 do mês
-

Xerxes
1° lugar - 150.888 pts -

Fábio Berbert de Paula
2° lugar - 70.662 pts -

Buckminster
3° lugar - 49.337 pts -

Alberto Federman Neto.
4° lugar - 39.502 pts -

Sidnei Serra
5° lugar - 25.392 pts -

edps
6° lugar - 25.464 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
7° lugar - 25.332 pts -

Daniel Lara Souza
8° lugar - 22.838 pts -

Mauricio Ferrari (LinuxProativo)
9° lugar - 22.555 pts -

Andre (pinduvoz)
10° lugar - 18.599 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: