Partição de tabelas no PostgreSQL
O artigo explica como particionar tabelas no PostgreSQL, o que pode ser útil para otimização do desempenho.
[ Hits: 15.447 ]
Por: David Augusto em 30/07/2012 | Blog: http://pedreirosdosoftware.wordpress.com

Teoria e criação da estrutura
Uma das melhores estratégias para diminuir o tempo de acesso à grandes volumes de dados é o particionamento de tabelas no PostgreSQL, o funcionamento é muito simples e bastante funcional.
Pensem que, como em um HD, você pode fazer várias partições, ou trabalhar com vários discos, organizando para que arquivos de A à D estejam na partição 1, arquivos de E à H estejam na partição 2, e assim por diante.
Desta forma, você sabe onde estão seus arquivos, e provavelmente, irá diretamente onde está o arquivo que procura. Com o Banco de Dados não é diferente, particionando as tabelas de acordo com o valor de um índice, ele irá para o local correto, trazendo dados mais rapidamente.
* Aviso: Questões referentes à modelagem além do particionamento, não fazem parte do artigo, nem se CPF deve ou não deve chave primária, nem mesmo o tipo de dado escolhido, é somente para tornar palpável o exemplo, nem mesmo qual a convenção utilizada para nomear tabela se case sensitive ou não e blá blá blá.
Considerem o seguinte modelo:
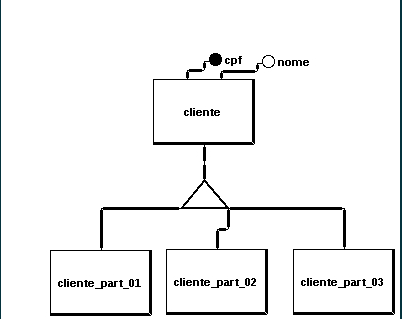
Temos nossa tabela "cliente" que é a pai (servindo apenas como um padrão) para as demais tabelas, ou seja, aquele famoso conceito de herança.
As tabelas "cliente_part_01', "cliente_part_02", "cliente_part_03"... Receberão os dados direcionados de acordo com o índice, que no caso é CPF.
Eis as SQLs:
cpf numeric(11,0) NOT NULL,
nome character varying(20),
CONSTRAINT cliente_pkey PRIMARY KEY (cpf)
);
CREATE TABLE cliente_part_01() INHERITS(cliente);
CREATE TABLE cliente_part_02() INHERITS(cliente);
CREATE TABLE cliente_part_03() INHERITS(cliente);
Particionamento
Tabelas criadas, partimos para a mágica do particionamento, o primeiro ponto é criar constraints para evitar que um registro seja adicionado fora de sua devida partição.No caso, vamos considerar que:
- cliente_part_01 receberá CPFs do número 000.000.000-00 até o número 300.000.000-00
- cliente_part_02 receberá CPFs do número 300.000.000-01 até o número 600.000.000-00
- cliente_part_03 receberá CPFs do número 600.000.000-01 até o número 999.999.999-99
Eis a SQL para criação disso:
ALTER TABLE cliente_part_02 ADD CHECK(cpf BETWEEN 30000000001 AND 60000000000);
ALTER TABLE cliente_part_03 ADD CHECK(cpf BETWEEN 60000000001 AND 99999999999);
O segundo passo é criar índices nas chaves primárias, para que o banco saiba onde deve procurar com mais rapidez.
* Nota: CPF foi criado como 'numeric(11,0)", índices podem não funcionar tão bem com esse tipo como com números inteiros, mas estou sendo apenas conceitual.
CREATE INDEX indice_cliente_part_02 ON cliente_part_02(cpf);
CREATE INDEX indice_cliente_part_03 ON cliente_part_03(cpf);
O próximo passo, é criar uma função que direcione a inserção para sua devida tabela:
RETURNS TRIGGER AS $$
BEGIN
IF(NEW.cpf BETWEEN 0 AND 30000000000) THEN
INSERT INTO cliente_part_01 VALUES(NEW.cpf, NEW.nome);
ELSIF(NEW.cpf BETWEEN 30000000001 AND 60000000000) THEN
INSERT INTO cliente_part_02 VALUES(NEW.cpf, NEW.nome);
ELSIF(NEW.cpf BETWEEN 60000000001 AND 99999999999) THEN
INSERT INTO cliente_part_03 VALUES(NEW.cpf, NEW.nome);
END IF;
RETURN NULL;
END;
$$ LANGUAGE PLPGSQL;
E por fim, a sua trigger:
BEFORE INSERT ON cliente FOR EACH
ROW EXECUTE PROCEDURE insere_cliente();
Testando
Para testar?Insira alguns registros, tipo:
INSERT INTO cliente(cpf, nome) VALUES (55555555555, 'Jonas o Motoqueiro');
INSERT INTO cliente(cpf, nome) VALUES (88888888888, 'Ruth Le-le-lemos');
Caso esteja utilizando o pgAdmin, basta olhar nas tabelas de partição, os dados estarão em seus devidos lugares e para a seleção, basta um:
Prático e funcional!
E existem várias estratégias para utilização de particionamento, até a utilização de tablespaces.
* Nota: Até a versão 8.4, para otimização, é recomendado alterar o parâmetro "constraint_exclusion" para "on", a partir do PostgreSQL 9.1, o valor "on" é default.
Fonte: ddl-partitioning « www.postgresql.org
Diagrama Entidade-Relacionamento com Dia e tedia2sql para o PostgreSQL
Sincronizando Dados do PostgreSQL no Elasticsearch
Criando um banco de dados espacial com PostgreSQL + PostGIS
Checklist de performance do PostgreSQL 8.0
Olá David, muito interessante a publicação desse tutorial, pois estou estudando na construção de banco de dados.
Pra mim seu artigo vai ajudar muito, tenho algumas bases que tendem ao infinito, e com esse tipo de fragmentação dar pra otimizar e muito as consultas. Favoritado!
Obrigado pela ajuda, Deus os abençoe e de tudo na vida para vocês
Prezado Obrigado, sou muito iniciante em postgre e com seu post consegui particionar. Mas tenho um problema, não consegui inserir os dados da tabela mãe para as filhas... o que estou errando?
Grato.
Antonio
Patrocínio

Destaques
Artigos
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
A evolução do Linux e as mudanças que se fazem necessárias desde o seu lançamento
Dicas
Cursor do mouse gigante no KDE Plasma
Integração do Flatpak e Flathub no Kubuntu (KDE Discover)
Habilitando suporte ao Flatpak e Flathub no Ubuntu
Tópicos
Top 10 do mês
-

Xerxes
1° lugar - 154.482 pts -

Fábio Berbert de Paula
2° lugar - 79.480 pts -

Alberto Federman Neto.
3° lugar - 44.839 pts -

Buckminster
4° lugar - 44.739 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 36.700 pts -

edps
6° lugar - 33.094 pts -

Sidnei Serra
7° lugar - 25.637 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 25.480 pts -

Daniel Lara Souza
9° lugar - 23.530 pts -

Andre (pinduvoz)
10° lugar - 22.655 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: