Não se afoguem mais em uma tonelada de Logs, ELK te salva! (Real-time)
Hoje em dia a análise de Big Data é cada vez mais importante por uma série de fatores, um deles é a tomada de decisão sobre o que fazer com determinado produto, serviço ou aplicação e, por conta disso, quem não faz análise de seus logs acaba ficando para trás. Isso é válido para empresas, Sysadmins, engenheiros, e principalmente a galera DevOps. Com base nesta questão, este artigo mostra uma das muitas formas de fazer isso, utilizando de tecnologias como: ELK, Docker e outras ferramentas essenciais para uma Infraestrutura Ágil, tudo isso em Real-time.
[ Hits: 19.970 ]
Por: Uriel Ricardo em 18/10/2016

Entendendo e configurando o Elk

No meu caso, irei colocar o arquivo.csv no diretório: /CSV
Neste diretório vou injetar um arquivo qualquer, se preferir pode colocar uma aplicação web, como por exemplo um Wordpress, e analisar os logs de erro ou até mesmo de acesso!
Para prosseguirmos, lhe aconselho a clonar meu repositório:
# git clone https://UrielRicardo@bitbucket.org/UrielRicardo/docker-elk.git
Para começar vamos no arquivo de orquestração da nossa aplicação, abra o arquivo: docker-compose.yml
Você vai ver algo assim:
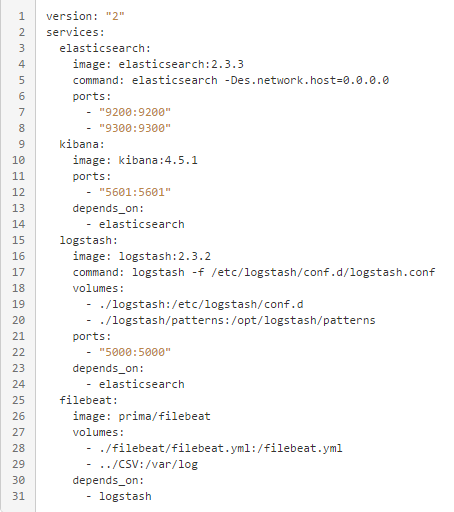
Da linha 1 até a linha 8, estamos configurando o serviço do Elasticsearch, ele é o servidor que vai armazenar todos esses logs, no caso estou utilizando de imagens prontas, esta está na versão 2.3, já estamos utilizando na versão 5.0.0-alpha, que é quase a mesma configuração!
Na linha 5, estamos "subindo" uma rede para conectar estes serviços!
Mais abaixo estamos expondo as portas 9200 e 9300.
Da linha 9 até a 14 estamos subindo o serviço do Kibana, onde estamos expondo a porta 5601, e definindo o "depends_on" para o Elasticsearch, isso nos garante que ele vai subir, só depois que o serviço do Elasticsearch subir.
Da linha 15 até a 24, estamos subindo o serviço do logstash, nele você pode notar que estamos passando o parâmetro "command: logstash -f /etc/logstash/conf.d/logstash.conf", este parâmetro está dizendo qual arquivo ele vai usar como configuração dentro do próprio container! Isso junto do parâmetro "Volumes" que nos permite sincronizar arquivos que estão em nosso host para dentro do container. Com as portas : "5000 e 5044" expostas ( a 5044 não está na imagem mas pode declarar) ele, assim como o Kibana, sobe só depois do Elasticsearch!
E por fim, das linhas 25 até a 31, estamos declarando o serviço do Filebeat que será usado para enviar os dados para nosso Logstash, estou usando assim por conta de ele me permitir envios remotos, seja via Linux ou Windows. Porém quem preferir pode descartar o uso dele e pegar os dados diretamente pelo Logstash. Nesta parte é onde eu declaro que o diretório que eu criei no host, o "/CSV" vai ser o meu "/var/log/" dentro do container! O mesmo faço para passar o arquivo de configuração do serviço!
Na próxima página iremos configurar o arquivo de configuração do Filebeat que vai nos permitir decidir quais dados serão enviados para o logstash.
2. Entendendo e configurando o Elk
3. Configurando o Filebeat.yml
4. Configurando o Logstash.conf
5. Acessando Kibana e analisando meu dados (Real-time)
Os bons tempos voltaram! Revivendo e revisitando o WindowMaker
GIMP - Colocando um desenho de traços sobre outra superfície
Introdução aos ambientes gráficos e gerenciadores de janelas menos conhecidos
Criando Fluxogramas? Use o Dia!
Parabéns pelo artigo, muito bem explicado! Achei você bem detalhista, lhe encontrei no LinkedIn, por acaso teria interesse em palestrar sobre isso na GDG DevFest em são Paulo?
E quanto ao artigo, teria este material em PDF?
Fantastico!
Especialista em Banco de Dados
[1] Comentário enviado por FelipeCoutinhoS em 19/10/2016 - 00:09h
Parabéns pelo artigo, muito bem explicado! Achei você bem detalhista, lhe encontrei no LinkedIn, por acaso teria interesse em palestrar sobre isso na GDG DevFest em são Paulo?
E quanto ao artigo, teria este material em PDF?
Olá Amigo, tudo bem? Lhe respondi na mensagem privada que me enviou, agradeço pelo feedback! Quanto ao pdf enviei para seu e-mail em anexo!
[2] Comentário enviado por cesar.dba em 20/10/2016 - 08:29h
Fantastico!
Especialista em Banco de Dados
Muito Obrigado pelo FeedBack =)
Assunto bem interessante. Obrigado pelo excelente artigo!
[5] Comentário enviado por eddye00 em 03/11/2016 - 09:22h
Assunto bem interessante. Obrigado pelo excelente artigo!
Eu que lhe agradeço, muito obrigador por ler meu artigo!
Amigo bom dia,
Poderia me enviar em pdf o artigo por e-mail?!
Especialista em Banco de Dados
Primeiramente você deve se preocupar em responder: o que é big data? Uma base grande? Grande quanto? Qual o maior gargalo em analisar big data? Como é feita a paralelização das análises?
Quando você conseguir responder estas perguntas, vai entender que não existe sentido em chamar logs gerados por um servidor de big data tal como não existe maneira de analisar uma base realmente grande em um único servidor. A maioria dos métodos de analise supõe que exista um driver (servidor ou pc aonde o código da análise é escrito) e vários workers (outros servidores que fazem a análise em paralelo). Métodos baseados no haboop tem um gargalo enorme (fora o problema da linguagem, só se pode usar Java), visto que existe muita leitura e escrita nos discos. Já frameworks mais novos, como o Apache Spark colocam toda a base a ser analisada em cache na memoria RAM, tornando as análizes até 100x mais rápidas que via hadoop. Além disto pode ser programado em Python, Scala, Java e R. Enfim, estou ilustrando este senário pois vejo muitos cursos de pós-graduação se propondo a abordar big data, porém o fazem de maneira totalmente equivocada, dando a impressão que qualquer base "grande" é big data.
Sei que seu propósito era apenas abordar alguns tools, porém gostaria de contribuir com estas reflexões.
Bom dia. Nobre amigo sigo todo o tutorial, mas não estou conseguindo encontrar esse comando docker-compose up -d. Poderia me ajudar? Fico no aguardo. Grato.
[9] Comentário enviado por iranmeneses em 05/05/2017 - 11:25h
Bom dia. Nobre amigo sigo todo o tutorial, mas não estou conseguindo encontrar esse comando docker-compose up -d. Poderia me ajudar? Fico no aguardo. Grato.
Tudo bem? você chegou a instalar o docker compose???
Patrocínio

Destaques
Artigos
O Journal no Linux para a guarda e consulta de logs do sistema
A evolução do Linux e as mudanças que se fazem necessárias desde o seu lançamento
Maquina modesta - a vez dos navegadores ferrarem o usuario
Fscrypt: protegendo arquivos do seu usuário sem a lentidão padrão de criptograr o disco
Dicas
Sway no Arch Linux: configuração Inicial sem enrolação
Resolvendo o bloqueio do Módulo Warsaw no Arch Linux (Porta 30900)
Tópicos
Loop infinito em uma media ponderada. (1)
Abrir um arquivo URL pelaLlinguagem C (5)
Top 10 do mês
-

Xerxes
1° lugar - 146.412 pts -

Fábio Berbert de Paula
2° lugar - 76.394 pts -

Buckminster
3° lugar - 46.620 pts -

Alberto Federman Neto.
4° lugar - 43.248 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 32.753 pts -

edps
6° lugar - 30.404 pts -

Sidnei Serra
7° lugar - 26.777 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 23.749 pts -

Daniel Lara Souza
9° lugar - 22.762 pts -

Andre (pinduvoz)
10° lugar - 20.928 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: