Linguagem C - Listas Duplamente Encadeadas
Neste artigo explicarei o que são listas duplamente encadeadas, como construí-las e suas vantagens e desvantagens. O pré-requisito para compreender bem o artigo é uma boa noção de ponteiros.

Introdução
Bom, antes de mais nada, se você quer aprender sobre listas duplamente encadeadas, precisa ao menos saber o motivo pelo qual vai utilizá-las. Esse motivo é utilizar memória esparsa de forma eficiente (e conseguir utilizar):
O código acima declara um vetor com 10 elementos do tipo int. Podemos imaginar que ele está organizado na memória da seguinte forma: A memória alocada para o vetor é contínua ("linear"). No espaço entre o início do vetor (vetor[0]) e o final (vetor[9]), não há nenhum outro tipo de informação que não seja 'int' e que não seja indexável pelo nome 'vetor'. Isso significa que você pode acessar todos os dados utilizando os números de 0 a 9, sem problema algum e que, entre os elementos vetor[3] e vetor[4] não há nenhum outro tipo de informação.
A memória alocada para o vetor é contínua ("linear"). No espaço entre o início do vetor (vetor[0]) e o final (vetor[9]), não há nenhum outro tipo de informação que não seja 'int' e que não seja indexável pelo nome 'vetor'. Isso significa que você pode acessar todos os dados utilizando os números de 0 a 9, sem problema algum e que, entre os elementos vetor[3] e vetor[4] não há nenhum outro tipo de informação.
Muito bom, com certeza. Saber onde estão nossas informações torna o acesso a elas muito eficiente. Mas, e se precisarmos armazenar informações em um ambiente cuja memória disponível seja esparsa? Em outras palavras, e se não houver espaço suficiente para alocar 10 elementos seguidos para nosso vetor? Então temos um problema.
Para solucionar esse problema, existe uma abstração de dados chamada "Lista Duplamente Encadeada". Existem também outros tipos de abstrações com o mesmo fim, que irão divergir em tempos de pesquisa, inserção, remoção, armazenagem, complexidade etc. Os cientistas da computação estão constantemente pesquisando novos algoritmos para implementações mais rápidas, ou menores, ou menos complexas, ou tudo isso ao mesmo tempo. Exemplos comuns são as listas encadeadas, árvores binárias e árvores binárias balanceadas (AVL ou RedBlack).
Cada uma dessas abstrações tem suas vantagens e desvantagens:
As listas encadeadas são extremamente eficientes (simples ou duplas), mas possuem tempo de pesquisa bem limitado - no pior caso, você precisa verificar todos os elementos para achar o que procura. Já as árvores binárias são estruturas de dados recursivas que oferecem um tempo de busca excepcional. Se uma árvore binária possui 1024 elementos, no pior caso da pesquisa serão 10 comparações para achar um elemento (em uma lista, seriam 1024 comparações).
O problema é que a implementação de árvores binárias é bem mais complexa que a implementação das listas encadeadas (até por sua natureza recursiva). Existe um outro problema com árvores binárias decorrente da forma com que o usuário insere os dados nela e chama-se degeneração em lista encadeada: se você inserir elementos de forma sequencial em uma árvore binária (1,2,3,4..), ela se "degenera" em uma lista encadeada, e perde sua propriedade de oferecer buscas eficientes.
Para resolver esse problema de degeneração, foram criados outros algoritmos (mais complexos) para balancear as árvores cada vez que um elemento é inserido e removido. Isso coloca as árvores binárias auto balanceáveis entre as estruturas de dados mais complexas que temos. Também torna o tempo de inserção um pouco maior, mas garante que a busca pela informação será excepcionalmente rápida. Ou seja, estamos sempre brincando com espaço de armazenagem, processamento e complexidade. Mas estes são temas para outros artigos.
Voltando às listas duplamente encadeadas:
Acima, define-se a estrutura LDE - nosso bloco básico de construção da lista duplamente encadeada. Além da(s) informação(s) que queremos armazenar, faz-se necessário mais dois elementos na estrutura: dois ponteiros, um para o próximo elemento da lista e um para o elemento imediatamente anterior. Pode-se concluir que o espaço gasto para armazenar cada elemento é maior, mas a flexibilidade fornecida pelos ponteiros vale a pena.
Em uma arquitetura 32 bits, cada ponteiro ocupa 4 bytes. Já em 64 bits, cada ponteiro irá ocupar 8 bytes. Se um int possui tamanho 4 bytes, e esta estrutura for implementada em um processador 64 bits, cada elemento da nossalista ocupará 4 + 8 + 8 bytes = 20 bytes. Um simples sizeof() mostrará o tamanho da estrutura...
Se você rodou o programa acima, viu que imprimiu 24 ao invés de 20 (64 bits). Se você alterar o programa acima para imprimir o tamanho de um int, e o tamanho de um ponteiro (64 bits), verá que o int terá 4 bytes, e cada ponteiro 8 bytes.
Então porquê o programa está mostrando 24 bytes? Alinhamento de memória.
Ponteiros são alinhados na memória automaticamente pelo compilador - isso se deve ao fato da natureza do acesso a memória dos registradores da CPU, mas isso é tema de ainda outro artigo... O importante é saber que a estrutura ocupa mais espaço que um simples elo de informação em um vetor mas que esse espaço vale cada bit a mais pela flexibilidade que os ponteiros vão nos fornecer para criar a abstração ilustrada na figura seguinte: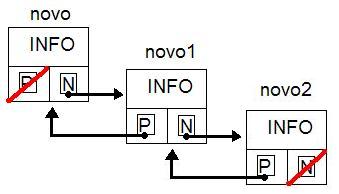 Como mostrado na figura, os elementos contêm informações sobre o próximo elemento e o elemento anterior. Isso significa que podemos alocar espaço de memória para um elemento e inserir nele informações sobre outros elos. Isso nos possibilita espalhar nossa lista de informações por uma memória esparsa de forma bem eficiente. A página seguinte explicará qual a base da implementação.
Como mostrado na figura, os elementos contêm informações sobre o próximo elemento e o elemento anterior. Isso significa que podemos alocar espaço de memória para um elemento e inserir nele informações sobre outros elos. Isso nos possibilita espalhar nossa lista de informações por uma memória esparsa de forma bem eficiente. A página seguinte explicará qual a base da implementação.
Agora que sabemos o motivo pelo qual utilizar uma lista duplamente encadeada, ou qualquer outro tipo de dados abstrato, vamos à implementação em si.
(A implementação mostrada neste artigo é bem simples, existem implementações muito mais complexas e robustas).
int vetor[10];
O código acima declara um vetor com 10 elementos do tipo int. Podemos imaginar que ele está organizado na memória da seguinte forma:

Muito bom, com certeza. Saber onde estão nossas informações torna o acesso a elas muito eficiente. Mas, e se precisarmos armazenar informações em um ambiente cuja memória disponível seja esparsa? Em outras palavras, e se não houver espaço suficiente para alocar 10 elementos seguidos para nosso vetor? Então temos um problema.
Para solucionar esse problema, existe uma abstração de dados chamada "Lista Duplamente Encadeada". Existem também outros tipos de abstrações com o mesmo fim, que irão divergir em tempos de pesquisa, inserção, remoção, armazenagem, complexidade etc. Os cientistas da computação estão constantemente pesquisando novos algoritmos para implementações mais rápidas, ou menores, ou menos complexas, ou tudo isso ao mesmo tempo. Exemplos comuns são as listas encadeadas, árvores binárias e árvores binárias balanceadas (AVL ou RedBlack).
Cada uma dessas abstrações tem suas vantagens e desvantagens:
As listas encadeadas são extremamente eficientes (simples ou duplas), mas possuem tempo de pesquisa bem limitado - no pior caso, você precisa verificar todos os elementos para achar o que procura. Já as árvores binárias são estruturas de dados recursivas que oferecem um tempo de busca excepcional. Se uma árvore binária possui 1024 elementos, no pior caso da pesquisa serão 10 comparações para achar um elemento (em uma lista, seriam 1024 comparações).
O problema é que a implementação de árvores binárias é bem mais complexa que a implementação das listas encadeadas (até por sua natureza recursiva). Existe um outro problema com árvores binárias decorrente da forma com que o usuário insere os dados nela e chama-se degeneração em lista encadeada: se você inserir elementos de forma sequencial em uma árvore binária (1,2,3,4..), ela se "degenera" em uma lista encadeada, e perde sua propriedade de oferecer buscas eficientes.
Para resolver esse problema de degeneração, foram criados outros algoritmos (mais complexos) para balancear as árvores cada vez que um elemento é inserido e removido. Isso coloca as árvores binárias auto balanceáveis entre as estruturas de dados mais complexas que temos. Também torna o tempo de inserção um pouco maior, mas garante que a busca pela informação será excepcionalmente rápida. Ou seja, estamos sempre brincando com espaço de armazenagem, processamento e complexidade. Mas estes são temas para outros artigos.
Voltando às listas duplamente encadeadas:
struct LDE {
int info;
struct LDE *proximo;
struct LDE *anterior;
};
Acima, define-se a estrutura LDE - nosso bloco básico de construção da lista duplamente encadeada. Além da(s) informação(s) que queremos armazenar, faz-se necessário mais dois elementos na estrutura: dois ponteiros, um para o próximo elemento da lista e um para o elemento imediatamente anterior. Pode-se concluir que o espaço gasto para armazenar cada elemento é maior, mas a flexibilidade fornecida pelos ponteiros vale a pena.
Em uma arquitetura 32 bits, cada ponteiro ocupa 4 bytes. Já em 64 bits, cada ponteiro irá ocupar 8 bytes. Se um int possui tamanho 4 bytes, e esta estrutura for implementada em um processador 64 bits, cada elemento da nossalista ocupará 4 + 8 + 8 bytes = 20 bytes. Um simples sizeof() mostrará o tamanho da estrutura...
struct LDE {
int info;
struct LDE *proximo;
struct LDE *anterior;
};
int main (void)
{
printf ("%d\n", sizeof(struct LDE));
return 0;
}
Se você rodou o programa acima, viu que imprimiu 24 ao invés de 20 (64 bits). Se você alterar o programa acima para imprimir o tamanho de um int, e o tamanho de um ponteiro (64 bits), verá que o int terá 4 bytes, e cada ponteiro 8 bytes.
Então porquê o programa está mostrando 24 bytes? Alinhamento de memória.
Ponteiros são alinhados na memória automaticamente pelo compilador - isso se deve ao fato da natureza do acesso a memória dos registradores da CPU, mas isso é tema de ainda outro artigo... O importante é saber que a estrutura ocupa mais espaço que um simples elo de informação em um vetor mas que esse espaço vale cada bit a mais pela flexibilidade que os ponteiros vão nos fornecer para criar a abstração ilustrada na figura seguinte:

Agora que sabemos o motivo pelo qual utilizar uma lista duplamente encadeada, ou qualquer outro tipo de dados abstrato, vamos à implementação em si.
(A implementação mostrada neste artigo é bem simples, existem implementações muito mais complexas e robustas).
{
int info;
struct LDE *prox;
struct LDE *ante;
};
Não ocupa 12 bytes?
Você está enganado!
Toda a vez que for criado um elemento desta estrutura, ela ocupará UM espaço para um inteiro e DOIS espaços para ponteiros.
Se considerar o GCC 32 bits, ambos, inteiro e ponteiro, tem 4 bytes. Logo, NESTE CASO, Gcc32 bits, a estrutura ocupará SIM 12 bytes de tamanho.
Para 10 elementos de vetores de inteiros se ocupará exatos 40 bytes (em archs e compiladores 32 bits).
Se for uma lista encadeada dos mesmos 10 elementos, se ocupará 120 bytes (10x o tamanho de uma estrutura e cada estrutura ocupa 4 bytes para o info, 4 bytes para o ponteiro prox e 4 bytes para o ponteiro ante).
As vantagens/desvantagens de uma lista encadeada não tem a ver com economia de espaço, mas sim com a flexibilidade. Uma lista encadeada pode crescer até o limite de memória disponível e sempre eu posso "alocar mais um". Um vetor eu preciso previamente decidir o tamanho. Se 10, serão 10 e ponto! Precisei de 11? Não dá para aumentar o vetor em tempo de execução (ops, até dá com realloc, mas ai e outro tiro no pé).
Outra vantagem das listas encadeadas é a possibilidade de inserir ordenado ou remover no meio. Imagine um vetor de 15000 posições, 10mil delas ocupadas (de 0 a 9999). Ele está ORDENADO e preciso inserir o valor X que pela ordenanação ele deve ser inserido em vet[15]. Como é vetor, eu preciso:
(a) mover [9999] para [10000], [998] para [999], ..., [15] para [16] para inserir o novo elemento em [15].
(b) ou inserir no final [10000] e executar algum algoritmo de ordenamento como o quick sort
Se for lista encadeada, basta inserir na posição e ajustar os ponteiros ante e prox corretamente.
Listas encadeadas e suas derivações (duplamente, circular, com header, etc) são estrutura de dados muito úties, resolvem um monte de problemas, mas em comparação com vetores simples são mais complicados de manipular e consomem mais memória por elemento SIM.