Linguagem C - Listas Duplamente Encadeadas
Neste artigo explicarei o que são listas duplamente encadeadas, como construí-las e suas vantagens e desvantagens. O pré-requisito para compreender bem o artigo é uma boa noção de ponteiros.

Parte 3: Inserindo dados
#define MALLOC(a) (a *) malloc ( sizeof(a) )
struct no
{
int info;
struct no *prox;
struct no *ant;
};
// não vou usar typedef - complica a vida de quem está começando
struct no *inicio;
struct no *fim;
struct no
{
int info;
struct no *prox;
struct no *ant;
};
// não vou usar typedef - complica a vida de quem está começando
struct no *inicio;
struct no *fim;
Bom, definida nossa estrutura, nossos ponteiros globais e nossa simplificação da malloc(), vamos começar a pensar em quais seriam os possíveis casos que uma função de inserção teria que analisar:
- O novo nó passará a ser o novo primeiro nó (inicio).
- O novo nó ocupará uma posição entre dois outros nós.
- O novo nó passará a ser o novo último nó (fim).
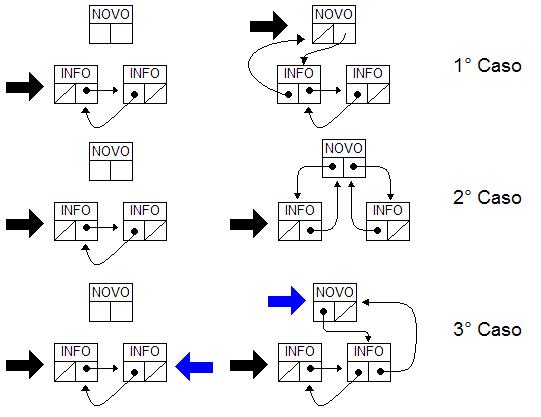
- As setas pretas GRANDES representam o ponteiro "inicio".
- As setas azuis GRANDES representam o ponteiro "fim".
- As demais "setinhas" representam as ligações dos ponteiros "prox" e "ant".
Bom, mostrada a teoria de como inserir um dado, podemos construir nossa função para inserir.
void inserir ( int info )
{
struct no *novo = MALLOC ( struct no );
struct no *atual;
if ( !novo )
{
perror ( "Malloc: " );
return ;
}
// atribuição do novo valor...
novo->info = info;
// MARCAÇÃO 1 - NÃO HÁ ELEMENTOS NA LISTA.
if ( !inicio )
{
novo->prox = NULL;
novo->ant = NULL;
inicio = novo;
fim = novo;
return ;
}
// se não for o primeiro elemento da lista...
// MARCAÇÃO 2 - CASOS DE INSERÇÃO
atual = inicio;
while ( atual )
{
if ( atual->info < info )
atual = atual->prox;
else
{
// MARCAÇÃO 3 - caso 2
if ( atual->ant )
{
novo->prox = atual;
novo->ant = atual->ant;
atual->ant->prox = novo;
atual->ant = novo;
return ;
}
// MARCAÇÃO 4 caso 1
novo->prox = atual;
novo->ant = NULL;
atual->ant = novo;
inicio = novo;
return ;
}
}
// MARCAÇÃO 5 - caso 3
fim->prox = novo;
novo->prox = NULL;
novo->ant = fim;
fim = novo;
return ;
}
{
struct no *novo = MALLOC ( struct no );
struct no *atual;
if ( !novo )
{
perror ( "Malloc: " );
return ;
}
// atribuição do novo valor...
novo->info = info;
// MARCAÇÃO 1 - NÃO HÁ ELEMENTOS NA LISTA.
if ( !inicio )
{
novo->prox = NULL;
novo->ant = NULL;
inicio = novo;
fim = novo;
return ;
}
// se não for o primeiro elemento da lista...
// MARCAÇÃO 2 - CASOS DE INSERÇÃO
atual = inicio;
while ( atual )
{
if ( atual->info < info )
atual = atual->prox;
else
{
// MARCAÇÃO 3 - caso 2
if ( atual->ant )
{
novo->prox = atual;
novo->ant = atual->ant;
atual->ant->prox = novo;
atual->ant = novo;
return ;
}
// MARCAÇÃO 4 caso 1
novo->prox = atual;
novo->ant = NULL;
atual->ant = novo;
inicio = novo;
return ;
}
}
// MARCAÇÃO 5 - caso 3
fim->prox = novo;
novo->prox = NULL;
novo->ant = fim;
fim = novo;
return ;
}
MARCAÇÃO 1:
A função inserir() primeiro certifica-se de que há uma lista para poder entrar em um loop de procura. Se não houver uma lista ( !inicio), elá criará uma.
if ( !inicio)
Se não há uma lista...
novo->prox = NULL;
novo->ant = NULL;
O ponteiro para o próximo nó do novo nó será nulo, assim como o ponteiro para o nó anterior, pois este será o único nó da lista atualmente.
inicio = novo;
fim = novo;
Isso "cria" a lista: toda vez que a função inserir() for chamada, ela fara a comparação "if(!inicio)", e como agora o ponteiro inicio terá um valor, esta comparação será falsa e a função executará a próxima parte. O ponteiro fim tem que ser iniciado também, pois se por algum motivo for usado sem nenhum valor por qualquer outra função, provavelmente causará quebra do programa.
MARCAÇÃO 2:
atual = inicio;
Esta atribuição garante que possamos varrer a lista conservando o endereço original do ponteiro inicio. "atual" é um ponteiro auxiliar de varredura. Para todas as função que varram a lista você precisará de um, a não ser que reconstrua a lista depois de todas as vezes que usar o ponteiro "inicio" ou "fim".
while (atual)
É auto-explicativo, mas vamos lá. Toda vez que o loop voltar ao inicio, ele fará uma comparação para checar se não chegou ao final da lista (ou ao inicio, dependendo da direção de sua varredura). Se atual for NULL (ou seja, fim da lista), o loop é cancelado.
if ( atual->info < info)
Este é o responsável por toda a função de inserção (Tá, exagerei um pouco...). Mas o que isso faz é comparar se a nova informação é maior do que a informação do nó atualmente sendo testado (note que ordem crescente foi a ordem escolhida para ordenação - certifique-se sempre de usar sinais/funções certas de comparação para a ordenação escolhida, errar aqui quase sempre significa quebra do programa).
atual = atual->prox;
Caso o if acima seja verdadeiro, ou seja, a nova informação é maior do que a informação atualmente sendo testada, esta linha faz com que 'atual' passe a ser o próximo item (Atribuições de endereço...).
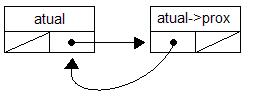
else {
Bom, isto é o que vai acontecer se a comparação der falsa (A nova informação é menor que o item atualmente sendo comparado - o que significa: inserção).
MARCAÇÃO 3:
if ( atual->ant )
Esta linha certifica-se de que o nó "atual" não é o primeiro nó da lista. Sim, qual o único nó da lista que possui um ponteiro "ant" com valor NULL? Sim, o primeiro nó. Então, se esta comparação for VERDADEIRA, significa que o valor de "atual->ant" NÃO É NULL, logo, não é o primeiro nó.
novo->prox = atual;
novo->ant = atual->ant;
atual->ant->prox = novo;
atual->ant = novo;
return ;
Bom, não tem como explicar isso melhor do que uma figura explicaria, então é só olhar como é feita a inserção na figura no início da página - CASO 2. Na figura, o ponteiro "atual" seria o quadrado INFO da direita. Soltem a imaginação!!!
MARCAÇÃO 4:
Estas próximas linhas poderiam estar dentro de um "else" do "if" da marcação 3... Sim, pois isto aqui só acontecerá se o "atual->ant" for NULL, ou seja, se o nó atual for o primeiro nó! Então vá lá ver na figura o caso 1 e novamente solte a imaginação...
MARCAÇÃO 5:
Se o programa sair do loop while(), significa que "atual" chegou ao último elemento e ainda assim, a nova informação era maior do que a informação atualmente sendo testada. Então é só inserir o elemento no final da lista. Bora pra figura ver o caso 3... e de novo, outra vez, novamente: solte a imaginação. O bom entendimento de listas encadeadas, árvores e afins está na visualização mental do negócio todo, quando conseguir ver as setinhas movimentando de uma lado para o outro para remover elementos ou inserí-los, você fará as funções de olhos fechados.
É, agora que inserimos os elementos não queremos eles lá mais não... vamos procurar e excluir esses @#$*%!
{
int info;
struct LDE *prox;
struct LDE *ante;
};
Não ocupa 12 bytes?
Você está enganado!
Toda a vez que for criado um elemento desta estrutura, ela ocupará UM espaço para um inteiro e DOIS espaços para ponteiros.
Se considerar o GCC 32 bits, ambos, inteiro e ponteiro, tem 4 bytes. Logo, NESTE CASO, Gcc32 bits, a estrutura ocupará SIM 12 bytes de tamanho.
Para 10 elementos de vetores de inteiros se ocupará exatos 40 bytes (em archs e compiladores 32 bits).
Se for uma lista encadeada dos mesmos 10 elementos, se ocupará 120 bytes (10x o tamanho de uma estrutura e cada estrutura ocupa 4 bytes para o info, 4 bytes para o ponteiro prox e 4 bytes para o ponteiro ante).
As vantagens/desvantagens de uma lista encadeada não tem a ver com economia de espaço, mas sim com a flexibilidade. Uma lista encadeada pode crescer até o limite de memória disponível e sempre eu posso "alocar mais um". Um vetor eu preciso previamente decidir o tamanho. Se 10, serão 10 e ponto! Precisei de 11? Não dá para aumentar o vetor em tempo de execução (ops, até dá com realloc, mas ai e outro tiro no pé).
Outra vantagem das listas encadeadas é a possibilidade de inserir ordenado ou remover no meio. Imagine um vetor de 15000 posições, 10mil delas ocupadas (de 0 a 9999). Ele está ORDENADO e preciso inserir o valor X que pela ordenanação ele deve ser inserido em vet[15]. Como é vetor, eu preciso:
(a) mover [9999] para [10000], [998] para [999], ..., [15] para [16] para inserir o novo elemento em [15].
(b) ou inserir no final [10000] e executar algum algoritmo de ordenamento como o quick sort
Se for lista encadeada, basta inserir na posição e ajustar os ponteiros ante e prox corretamente.
Listas encadeadas e suas derivações (duplamente, circular, com header, etc) são estrutura de dados muito úties, resolvem um monte de problemas, mas em comparação com vetores simples são mais complicados de manipular e consomem mais memória por elemento SIM.