Tutorial hadoop - Guia prático de um cluster com 3 computadores
Seu chefe disse que para aumentar o lucro da empresa é necessário criar um buscador de site (ex.: Google), ou seja, fazer uma pesquisa de forma eficiente em um arquivo com 10GB de tamanho por exemplo. Então conheça na prática como a ferramenta hadoop pode lhe ajudar.

Descrição
Hadoop é um sistema computacional distribuído oferecendo agilidade na análise de arquivos extensos. Robusto contra falha nos nodos do cluster através de serviços que monitoram os nodos e a aplicação que manuseia o arquivo.
Descrição resumida das principais ferramentas de cluster hadoop:
O sistema hadoop realiza duas tarefas básicas, dividir o arquivo a ser computado entre os nodos usando um sistema de arquivo próprio (ferramenta HDFS) e a outra tarefa é executar a aplicação nos nodos (ferramenta MapReduce ou Yarn). Nesta primeira parte trataremos da configuração do serviço HDFS.
Recursos necessários para montar o cluster:
Obs.: O sistema também funcionará apenas com dois computadores (um namenode e um datanode).
* namenode é o principal elemento do sistema de arquivos do cluster, é o gerenciador do sistema de arquivos, monitora a saúde dos computadores escravos (datanodes), medindo os recursos de disco rígido e memória disponível. Tem a função de fragmentar o metadado em blocos e repassar para os datanotes. Lembrando que para aumentar a robustez contra falha nos nodos, os blocos sao replicados por 3 (configuração padrão).
Obs.: nos meus testes eu deixei em torno de 10 GB disponíveis no HD. Se não configurado, o hadoop irá alocar automaticamente o espaço disponível no seu HD para montar o sistema de arquivo DFS.
** datanode - o sistema criado pelo namenode é chamado HDFS. Ele basicamente cria blocos de 128 MB (config default) entre os computadores datanode. Conforme o tamanho do metadado a ser processado, mais blocos serão criados. Para aumentar a robustez do sistema o namenode replicará os dados do metadado aos datanodes do cluster.
Na imagem abaixo é possível ver a ilustração de sistema de arquivos HDFS.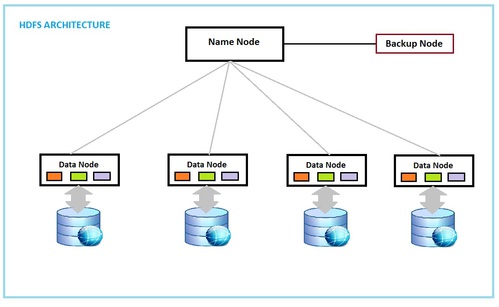 O metadado a ser computado por uma aplicação é dividido pelo namenode em blocos de 128 ou 64 MB enviados aos datanodes. Cada cor simboliza um bloco. As cores iguais entre os nodos representam a replicação dos dados para proteger a aplicação contra possíveis falhas em alguns dos nodos e a aplicação continue executando.
O metadado a ser computado por uma aplicação é dividido pelo namenode em blocos de 128 ou 64 MB enviados aos datanodes. Cada cor simboliza um bloco. As cores iguais entre os nodos representam a replicação dos dados para proteger a aplicação contra possíveis falhas em alguns dos nodos e a aplicação continue executando.
Este tutorial, foi implementado em sistema operacional Linux. Nas próximas paginas iremos descrever os principais componentes de configuração do cluster, arquivos de configuração, iniciação dos serviços e o exemplo de execução de uma aplicação contadora de palavras no cluster.
Descrição resumida das principais ferramentas de cluster hadoop:
O sistema hadoop realiza duas tarefas básicas, dividir o arquivo a ser computado entre os nodos usando um sistema de arquivo próprio (ferramenta HDFS) e a outra tarefa é executar a aplicação nos nodos (ferramenta MapReduce ou Yarn). Nesta primeira parte trataremos da configuração do serviço HDFS.
Recursos necessários para montar o cluster:
- 1x computador mestre para rodar o namenode*
- 2x computadores escravos para datanode**
Obs.: O sistema também funcionará apenas com dois computadores (um namenode e um datanode).
* namenode é o principal elemento do sistema de arquivos do cluster, é o gerenciador do sistema de arquivos, monitora a saúde dos computadores escravos (datanodes), medindo os recursos de disco rígido e memória disponível. Tem a função de fragmentar o metadado em blocos e repassar para os datanotes. Lembrando que para aumentar a robustez contra falha nos nodos, os blocos sao replicados por 3 (configuração padrão).
Obs.: nos meus testes eu deixei em torno de 10 GB disponíveis no HD. Se não configurado, o hadoop irá alocar automaticamente o espaço disponível no seu HD para montar o sistema de arquivo DFS.
** datanode - o sistema criado pelo namenode é chamado HDFS. Ele basicamente cria blocos de 128 MB (config default) entre os computadores datanode. Conforme o tamanho do metadado a ser processado, mais blocos serão criados. Para aumentar a robustez do sistema o namenode replicará os dados do metadado aos datanodes do cluster.
Na imagem abaixo é possível ver a ilustração de sistema de arquivos HDFS.
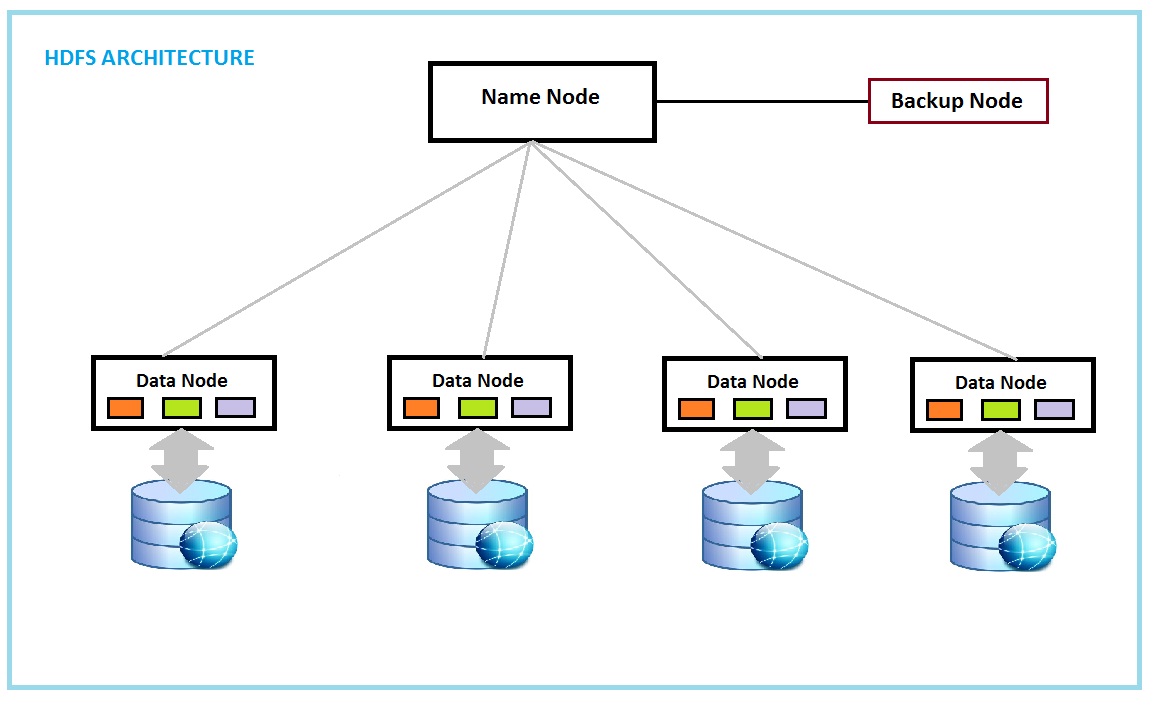
Este tutorial, foi implementado em sistema operacional Linux. Nas próximas paginas iremos descrever os principais componentes de configuração do cluster, arquivos de configuração, iniciação dos serviços e o exemplo de execução de uma aplicação contadora de palavras no cluster.