Introdução a CGI com a RFC 3875
Esta é uma tradução livre, com alguns comentários sobre CGI do ponto de vista da RFC 3875. Espero que seja útil para alguém, assim como foi para mim.
[ Hits: 18.485 ]
Por: Perfil removido em 18/05/2012

RFC 3875 e Comentários de Tradução - I
Convenções de Notação e Gramática
Todos os mecanismos definidos na RFC 3875, são descritos em um formato BNF - Backus-Naur Form - similar ao utilizado na RFC 822. Estes elementos são 'case sensitive', a menos que dito em contrário. O básico de BNF define:- nome = definição : O nome de uma regra e sua definição são separados pelo caractere de igualdade (=).
- "Literal" : Marcações em aspas duplas (" ") em torno de um texto literal, exceto para uma marcação entre angle-brackets ( < >).
- regra_1 | regra_2 : Alternativas são marcadas por uma barra vertical.
- (regra_1 regra_2 regra_3) : Elementos entre parêntesis são tratados como uma regra única.
- *regra : Uma regra precedida por um asterisco pode ser zero ou mais ocorrências. O formato n*m(regra) indica que a regra tem no mínimo 'n' ocorrências, e no máximo 'm'.
- [regra] : Um elemento inserido entre colchetes é opcional. Equivale a *1 regra.
Regras Básicas
A RFC 3875 define os termos da CGI em função de caracteres, assim em cada sistema, não interesta como eles são definidos em termos de bits e Bytes. A exceção é a definição de OCTETO.
Observe que NL (newline) não precisa ser necestariamente um único caractere, mas pode ser uma combinação de caracteres de controle como retorno de carro e nova linha, simplesmente nova linha ou simplesmente retorno de carro. Isto significa que a definição de NL depende do sistema operacional hospedeiro.
Codificação de uma URL
Algumas variáveis e construções usadas na especificação são descritas como 'url-codificadas'. A codificação de URLs é descrita na RFC 2396. Em resumo, uma URL codificada é uma cadeia de caracteres representada na forma de um caractere de percentual (%) seguida de por dois hexadecimais que representam um octeto.Um caractere escapado com barra (\) representa um caractere gráfico da tabela -ASCII na língua inglesa. Observe que, de acordo com o contexto, alguns caracteres são considerados inseguros (reservados). Isso ocorre, pois são caracteres utilizados pelo Sistema Operacional com uma função especifica.
Assim, para codificar uma cadeia de caracteres, todos os caracteres reservados, ou proibidos, são substituídos por suas representações escapadas. Este conjunto de caracteres pode variar de acordo com o contexto, mas são definidos sempre dentro deste super conjunto.
Reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | "$" |"," | "[" | "]"
Qualquer caractere fora do conjunto dos Reservados, não deve ser escapado. Outras regras básicas para definir uma URL são:

Invocando o Script
- Responsabilidades do ServidorO Servidor atua como uma aplicação Gateway que recebe as requisições do cliente, seleciona um script CGI para manipular a requisição, converte a requisição do cliente para uma requisição CGI, executa o script e converte a resposta CGI para uma resposta ao cliente.
Quando processando a requisição do cliente, o Servidor é responsável por implementar qualquer protocolo, ou autenticação, e segurança no nível de transporte da comunicação.
O Servidor PODE também funcionar de modo não transparente, modificando a requisição, ou a resposta, para prover algum serviço adicional, como uma transformação de tipo ou redução de protocolo.
O Servidor DEVE realizar traduções e conversões de protocolo baseado na requisição do cliente para adequar a especificação. O Servidor deve adequar-se a quaisquer transformações necessárias para atender à requisição do cliente.
O Servidor não deve executar qualquer script até que todas as credenciais necessárias sejam checadas, se existentes.
Seleção de Script
O Servidor determina qual script CGI será executado baseado na URL fornecida pelo cliente. esta URL incluí uma hierarquia de caminhos (PATH) composta por separadores de diretórios, normalmente uma contra barra ( / ).Uma URL é parte de uma definição maior, chamada de URI. O modo como o Servidor interpreta a URL deve ser de acordo com a padronização da URI definido na RFC 2396.
O Servidor PODE preservar o formato da URL de acordo com a requisição do cliente, ou PODE selecionar um formato canônico da URI, ou ainda, implementar qualquer seleção de URI baseada no conjunto de dados recebidos via URL.
Por exemplo, definir meta-variáveis como SCRIPT-NAME, PATH_INFO ou QUERY_STRING (de acordo com RFC 2396) baseado nas meta-variáveis padrão.
Onde:
- <scheme> - É um protocolo encontrado no Servidor (HTTP ou HTTPS).
- <server-name> - É o FQDN do Servidor ou seu endereço IP ou um nome que puder ser resolvido por algum mecanismo de resolução de nomes presente.
- <server-port> - É a porta (TCP ou UDP) que escuta as requisições.
- <script-path> e <extra-path> - O caminho até o script.
- <query-string> - São as respectivas meta-variáveis.
Execução do Script
O script é invocado em uma base por sistema. A menos que especificado um modo alternativo, a execução se dá como um programa executável.O Servidor prepara a requisição CGI, como descrito a seguir, o que disponibiliza imediatamente todos os dados da requisição. Mas o script pode ser executado mesmo antes de todos os dados estarem disponibilizados para ele.
A execução gera uma resposta que será disponibilizada, como veremos mais adiante.
Se qualquer condição de erro ocorrer, o script deve estar preparado para lidar com ela. O Servidor PODE interromper a execução por qualquer motivo, e o script DEVE estar preparado para lidar com o término anormal.
A requisição CGI
As informações sobre a requisição vem de dois lugares diferentes; as meta-variáveis da requisição e qualquer mensagem associada ao corpo da mensagem.Meta-variáveis da Requisição
As meta-variáveis contém dados sobre a requisição passados pelo Servidor para o script, e são acessadas pelo script em uma base definida por sistema.Meta-variáveis são identificadores 'case insentitive', e não aceitam espaços em seus nomes. O caractere sublinhado (underscore) pode ser utilizado para fazer o papel de espaços.
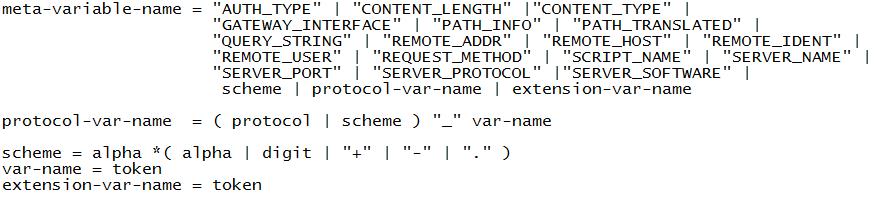
Esta especificação não distingue entre o comprimento zero (NULL) e valores ausentes. Por exemplo, um script não pode distinguir entre duas requisições com ou sem dados.
Tanto: http://host/script, quanto: http://host/script/?, possuem a meta-variável: QUERY_STRING nula (ou vazia).
Daí a regra seguinte:
Meta-variáveis DEVEM ser 'case sensitive', exceto se notação em contrário.
AUTH-TYPE
Esta variável identifica qualquer mecanismo usado pelo Servidor para autenticação do usuário. Seu conteúdo é ''case insentitive'' e definido pelo protocolo cliente ou pela implementação do Servidor.Para HTTP, se a requisição do cliente requisitar autenticação para acesso externo, então o Servidor DEVE configurar o valor esta variável para 'auth-scheme' no campo cabeçalho da autenticação da requisição.
Os esquemas de autenticação HTTP são descritos pela RFC 2617. Os valores válidos são:
auth-scheme = "Basic" | "Digest" | extension-auth
extension-auth = token
CONTENT_LENGTH
Esta variável contém o tamanho (em OCTETOS) do corpo da mensagem que é anexado após o fim do cabeçalho CGI. Se não houver dados no corpo da requisição, o valor informado será NULL ou não deve ser informada a variável.O Servidor DEVE configurar esta meta-variável se, e somente se, a requisição for acompanhada de dados no seu corpo. Este valor deve refletir o comprimento em octetos após o Servidor remover quaisquer códigos de transferência ou conteúdo.
CONTENT-TYPE
Se a requisição incluir um corpo, esta meta-variável é configurada para um dos tipos de mídia da Internet (MIME TYPES) definidos pela RFC 2046 para descrever este corpo em um formato de arquivo válido.media-type = type "/" subtype *( ";" parameter )
type = token
subtype = token
parameter = attribute "=" value
attribute = token
value = token | quoted-string
O tipo, subtipo e os atributos do parâmetro são 'case insentitive'. Valores de parâmetros são 'case sensitive'. Os tipos MIME que são aceitos por HTTP são descritos na especificação HTTP/1.1.
Não há um valor padrão para esta variável. Se e somente se, ela não for definida, o script PODE tentar determinar o tipo MIME pelos dados recebidos. Se o tipo se mantiver desconhecido, então o script PODE escolher e assumir um tipo baseado em "application/octet-stream", ou PODE rejeitar a requisição com um erro.
Cada tipo MIME, define um conjunto de parâmetros mandatórios ou opcionais. Isso pode incluir um parâmetro como um conjunto de caracteres com um valor 'case insentitive' definindo a página de código do corpo da mensagem.
Se este valor for omitido, então o valor padrão deve ser derivado de acordo com as regras seguintes, até que uma seja atendida.
- PODE haver um conjunto de caracteres definido para alguns tipos MIME;
- O padrão para texto puro é ISO-8859-1;
- Qualquer padrão definido na especificação do tipo MIME;
- us-ASCII.
O Servidor DEVE configurar este meta-variável 'if' um campo 'Content-Type' estiver presente no cabeçalho da requisição do cliente. Se o Servidor receber uma requisição com uma entidade anexada, mas sem um cabeçalho 'Content-Type', ele PODE tentar determinar o tipo correto, ou omitir esta meta-variável.
GATEWAY_INTERFACE
Esta variável DEVE ser configurada para quaisquer dialetos de CGI (diferentes de CGI/1.1, definida neste documento) sendo utilizados pelo Servidor para se comunicar com o script. O valor pode incluir um valor menor e outro maior para diferentes versões suportadas.PATH_INFO
A variável PATH_INFO, especifica um caminho para ser interpretado pelo script CGI. Ela identifica um recurso, ou sub-recurso, para ser retornado pelo script CGI, e é derivado da porção da URL seguido da parte que identifica o próprio nome do script.Ao contrário de um caminho da URL o PATH_INFO não é uma URL codificada, e não deve conter parâmetros de caminho.
path = lsegment *( "/" lsegment )
lsegment = *lchar
lchar = <any TEXT or CTL except "/">
O valor de PATH_INFO é considerado 'case sensitive', e o Servidor DEVE preservar o caminho como presente na URL da requisição. O Servidor PODE impor restrições e limitações aos valores que são permitidos para PATH_INFO, e PODE rejeitar a requisição com um erro, se ele encontrar quaisquer valores considerados não aceitos.
Isto PODE incluir quaisquer requisições que resultem na raiz (" / "), inclusive as que representam a perda de dados da requisição.
PATH_TRANSLATED
Esta variável é derivada de PATH_INFO, passando o valor como uma URI local e realizando quaisquer traduções de endereços virtual para físico. O conjunto de caracteres permitidos é definido em uma base por sistema.A localização do arquivo é acestada por uma requisição do tipo:
Onde: <extra-path> é uma URL-CODIFICADA que representa uma versão de PATH_INFO, onde os caracteres ";", "=" e "?" são reservados.
QUERY-STRING
Esta variável contém uma URL-CODIFICADA para uma busca, ou uma cadeia, de caracteres como parâmetros. As informações neste campo afetam, ou refinam, o retorno fornecido pelo script. A sintaxe para uma URL-CODIFICADA é descrita na RFC 2396 e seu valor é 'case sensitive'.query-string = *uric
uric = reserved | unreserved | escaped
Quando analisando e decodificando a cadeia QUERY_STRING, os detalhes desta análise, os caracteres reservados e o suporte para caracteres não US-ASCII dependem do contexto.
O Servidor DEVE sempre configurar esta variável. Se a URL enviada não fornecer um componente para QUERY_STRING, então, seu valor será vazio (" ").
REMOTE_ADDR
O valor desta variável DEVE ser configurado para o endereço de rede do cliente, que está enviando a requisição ao Servidor. O formato para IPV6 é descrito em RFC 3513.hostnumber = ipv4-address | ipv6-address
ipv4-address = 1*3digit "." 1*3digit "." 1*3digit "." 1*3digit
ipv6-address = hexpart [ ":" ipv4-address ]
hexpart = hexseq | ( [ hexseq ] "::" [ hexseq ] )
hexseq = 1*4hex *( ":" 1*4hex )
REMOTE_HOST
Esta variável contém o FQDN que o cliente enviou na requisição, se disponível, ou NULL. FQDN são descritos em RFC 1034 e 1123. Nomes de domínios são 'case insentitive'.hostname = *( domainlabel "." ) toplabel [ "." ]
domainlabel = alphanum [ *alphahypdigit alphanum ]
toplabel = alpha [ *alphahypdigit alphanum ]
alphahypdigit = alphanum | "-"
REMOTE_IDENT
Esta variável PODE ser utilizada para prover informações sobre a identidade informada sobre a conexão com na RFC 1413 requerida pelo agente, se disponível. O Servidor pode escolher NÃO suportar esta função ou ignorar uma resposta.
REMOTE_USER
Esta variável provê uma identidade do usuário fornecida pelo cliente, como parte de sua autenticação. Se a requisição exigir autenticação HTTP (AUTH_TYPE como "Basic" ou "Digest"), então, o valor de REMOTE_USER DEVE ser configurado para o valor fornecido como o ID do usuário.REQUEST_METHOD
Esta meta-variável DEVE ser configurada com o método que será utilizado pelo script para procestar a requisição. O método é case sensitive. Os métodos são descritos em detalhes na especificação HTTP/1.0 e HTTP/1.1.method = "GET" | "POST" | "HEAD" | extension-method
extension-method = "PUT" | "DELETE" | token
SCRIPT_NAME
Esta variável DEVE ser configurada para um valor URI (não codificada) de modo que possa identificar o nome do script CGI. Sua sintaxe é igual a PATH_INFO.SERVER_NAME
Esta variável DEVE ser configurada com o nome do Servidor para o qual a requisição do cliente foi enviada. este valor é 'case insentitive' ou um endereço IP.server-name = hostname | ipv4-address | ( "[" ipv6-address "]" )
Quando vários Servidores virtuais compartilham o mesmo endereço IP, então, o Servidor utiliza o conteúdo da requisição para definir o Host virtual correto para enviar a requisição.
SERVER_PORT
Esta variável DEVE ser configurada para o valor da porta TCP/IP, informada pelo cliente na requisição, para o qual a mesma deve ser enviada. Se este valor for omitido pelo cliente, então o valor padrão para HTTP (80) ou HTTPS (443) será utilizado.SERVER_PROTOCOL
Esta variável DEVE ser configurada como nome e a versão do protocolo de aplicação usado para a requisição CGI. Isso PODE ser diferente da versão utilizada pelo Servidor para se comunicar com o cliente.
Este valor é 'case insentitive', apesar de que usualmente é recebido em maiúsculas. O protocolo não é necestariamente o mesmo enviado através da URL. Por exemplo, uma requisição que alcançou o script através de HTTP pode ser utilizada em um esquema HTTPS.
HTTP-Version = "HTTP" "/" 1*digit "." 1*digit
extension-version = protocol [ "/" 1*digit "." 1*digit ]
protocol = token
SERVER_SOFTWARE
A variável DEVE ser configurada com o nome e a versão do software que fez a requisição CGI. Isso DEVE ser o mesma informação que o Servidor retorna ao cliente quando uma descrição é retornada, se houver.product = token [ "/" product-version ]
product-version = token
comment = "(" *( ctext | comment ) ")"
ctext = <any TEXT excluding "(" and ")">
2. RFC 3875 e Comentários de Tradução - I
3. RFC 3875 e Comentários de Tradução - II
4. Acknowledgements
PuTTY - Release 0.66 - Parte III
Como explicar ao leigo o que é Sistema Operacional
Trabalhando com a extensão .tar
Qmail + Patches + Performance Tuning, the Debian AMD64 way
Catalyst Framework Perl - (parte 2)
Programando uma Intranet com Apache, MySQL e Perl (parte 1)
Catalyst Framework Perl (parte 1)
Catalyst Framework Perl - Parte III
Sensacional a explicação dada. Parabéns, amigo, pela paciência e boa vontade para compartilhar o seu conhecimento!
Meus sinceros agradecimentos.
Olá,
Gostaria de um passa-a-passo que como fazer meu PC rodar shell scripts pelo Browser.
Obrigado
Patrocínio

Destaques
Artigos
File Browser: Crie sua Nuvem Pessoal Privada
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
Dicas
Otimizando o uso de Memória RAM no Ubuntu com zRAM
Usando alias no Terminal para comandos longos
Simplificando o manual do terminal no Ubuntu 26.04
Bloqueio da instalação e reinstalação do Snap (snapd) no Ubuntu
Tópicos
Continuando meus tópicos anteriores (11)
GLPI Cards de filtros de pesquisa (2)
Top 10 do mês
-

Xerxes
1° lugar - 158.927 pts -

Fábio Berbert de Paula
2° lugar - 81.520 pts -

Alberto Federman Neto.
3° lugar - 45.521 pts -

Buckminster
4° lugar - 43.033 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 38.004 pts -

edps
6° lugar - 33.601 pts -

Mauricio Ferrari (LinuxProativo)
7° lugar - 25.915 pts -

Sidnei Serra
8° lugar - 25.782 pts -

Daniel Lara Souza
9° lugar - 23.955 pts -

Andre (pinduvoz)
10° lugar - 23.178 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: